


Die Herausforderungen der digitalen Transformation betreffen nahezu jedes Unternehmen. Industrie 4.0 und das Internet of Things sind keine Visionen, sondern in weiten Teilen der Wirtschaft bereits Realität. Um in diesem dynamischen Umfeld erfolgreich zu agieren, ist es wichtig, typische Fehler bei der Datenanalyse zu vermeiden. Viele dieser Fehler resultieren aus einer mangelnden Kenntnis statistischer Zusammenhänge, sodass es zu Fehlinterpretationen der Ergebnisse kommen kann.
Die Bedeutung der Datenanalyse im Kontext von Big Data
Im Umfeld von Big Data werden in den Unternehmen riesige Datenbestände zusammengetragen. Neben den Unternehmensdaten sollen auch Sensordaten, Geodaten und die Daten aus den Social Media genutzt werden. Selbstverständlich ist auch das World-Wide-Web eine schier unerschöpfliche Quelle für immer neue Daten. Ziel des gesamten Datenmanagements ist es, aus diesen Datenbergen Informationen zu gewinnen, mit denen die unternehmerischen Entscheidungen verbessert werden. Der Gedanke ist einleuchtend: Gelingt es, in den Datenfluten Muster, Zusammenhänge, Auffälligkeiten und Kausalitäten zu identifizieren, kann das Unternehmen mit diesen Informationen einen Vorsprung vor der Konkurrenz erreichen und die eigene Wettbewerbsposition stärken. Des Weiteren werden die Erkenntnisse der Datenanalyse verwendet, um Risiken frühzeitig zu erkennen und entsprechend rechtzeitig zu reagieren.
Die Erhebung der Massendaten wird nur dann das volle Potential entfalten, wenn bei der anschließenden Datenanalyse typische Fehler vermieden werden. Es reicht nicht aus, Daten zu sammeln und zu speichern, denn aus den Datensätzen lassen sich erst mit Hilfe geeigneter Analyseverfahren wertvolle Informationen ableiten. Mittlerweile stehen den Unternehmen leistungsfähige Business Analytics Tools zur Verfügung, mit denen sogar Mitarbeiter ohne Programmierkenntnisse Datenauswertungen im Self-Service vornehmen können. Es ist jedoch wichtig, die Auswahl der Business Intelligence Tools möglichst optimal auf die Informationsbedarfe des Unternehmens und der Fachabteilungen abzustimmen. Außerdem sollte mit den entsprechenden Maßnahmen zur Qualifizierung dafür gesorgt werden, dass die modernen Informationstechnologien auch korrekt angewendet werden. Schließlich bedarf es der organisatorischen Verankerung und unternehmensweiten Sensibilisierung für den Bereich Datenmanagement, damit mit den Datenanalysen der erhoffte Erkenntnisfortschritt erreicht wird.
Gelingt es jedoch, die genannten Voraussetzungen zu schaffen und Fehler zu vermeiden, werden Daten zum wertvollen „Rohstoff“ für das Unternehmen. Im Informationszeitalter ist Wissen entscheidend und der Umgang mit Daten wird zum Erfolgsfaktor. Damit aus den Massendaten das wird, was häufig auch als „binäres Gold“ bezeichnet wird und den Mehrwert betont, der mit Datenanalysen erreicht werden kann, sollten Unternehmen den Prozess der Datenanalyse kritisch betrachten und Fehlerquellen eliminieren. Generell ist es wichtig, dass Unternehmen nicht nur ungeplant massenhaft Daten sammeln, sondern eine konkrete, nachvollziehbare Strategie des Datenmanagements implementiert wird.
Fehlerquellen bei der Datenanalyse: Stolpersteine auf dem Weg zu Big Data
Obwohl die Fehlerquellen ebenso wie die Erfolgspotentiale bei der Datenanalyse sich von Unternehmen zu Unternehmen unterscheiden und Branchenspezifika oder Analyseschwerpunkte sowie die Qualifikation der Analysten wichtige Faktoren sind, gibt es einige Fehler, die für diesen Bereich des Datenmanagements typisch sind.
Missverständnisse bei der Interpretation grundlegender statistischer Begriffe
Datenanalyse ist das Anwenden von statistischen Methoden mit dem Ziel, aus numerischen Daten Informationen zu generieren. Um Daten korrekt zu analysieren und vor allem, um die Ergebnisse der Datenanalysen richtig zu interpretieren, sollten bei den Analysten grundlegende Statistikkenntnisse vorhanden sein. Obwohl die Business Intelligence Tools die mathematischen Prozesse der statistischen Auswertung übernehmen, ist es wichtig, hinsichtlich der Begriffe die Übersicht zu behalten.
Besonders die Begriffe statistische Signifikanz und statistische Relevanz werden bei der Interpretation oft verwechselt. Statistische Signifikanz wird dann mit statistischer Relevanz gleichgesetzt, was zur Ableitung falscher Konsequenzen führen kann, denn beide Größen messen unterschiedliche Sachverhalte. Die statistische Signifikanz erlaubt Aussagen darüber, wie wahrscheinlich es ist, dass ein Phänomen zufällig aufgetreten ist. Ist etwas statistisch nicht signifikant, bedeutet das lediglich, dass neben dem zufälligen Auftreten keine systematische Variation bewiesen wurde. Die Betonung liegt hierbei auf „bewiesen wurde“, denn auch wenn kein statistischer Beweis vorliegt, muss dies nicht zwingend bedeuten, dass es keine Effekte gibt. Es bedeutet lediglich, dass diese Effekte nicht bewiesen werden können.
Werden ausreichend viele Beobachtungen zugrunde gelegt, ist es möglich, auch für sehr kleine Differenzen eine statistische Signifikanz festzustellen. Mit zunehmender Größe der Stichprobe können immer kleinere Unterschiede als statistisch signifikant identifiziert werden. Das ist auch der Grund, warum der Begriff der statistischen Signifikanz von dem der statistischen Relevanz abgegrenzt werden muss. Die statistische Relevanz ist die Kennzahl für die Stärke des Effekts, der aus dem festgestellten Unterschied resultiert. Zu diesem Zweck wird zunächst die Größe dieses Unterschieds berechnet und diese dann in Relation gesetzt zur Streuung der Daten.
Die statische Relevanz ist somit nicht von der Größe der Stichprobe abhängig. Je größer die Varianz der Zufallsvariablen ist, desto geringer ist die Stärke des Effekts, der mit dem Unterschied verbunden ist. Die Bedeutung von Ergebnissen der Datenanalyse muss mit der statistischen Relevanz, die Aussagen über die Stärke des Effekts erlaubt, beurteilt werden. Häufig wird für diese Beurteilung jedoch die statische Signifikanz herangezogen, was selbstverständlich zu Fehlinterpretationen führt.
Verwechslung von Korrelationen und Kausalitäten
Auch im Hinblick auf diese beiden Begriffe gibt es bei der Interpretation der Ergebnisse einer Datenanalyse immer wieder Missverständnisse. Hat die Datenanalyse ergeben, dass zwei Größen miteinander korrelieren, wird oft fälschlicherweise davon ausgegangen, dass sich diese beiden Größen gegenseitig bedingen, also die eine Größe die andere bestimmt. Es ist jedoch selbst mit komplexen statistischen oder ökonometrischen Modellen nicht möglich, derartige Kausalitäten zu beweisen. Oft wird eingewendet, dass das zugrundeliegende Datenmodell theoretisch fundiert sei. Dabei wird vernachlässigt, dass dieses Modell selbst falsch sein kann. Aus diesem Grund werden in der Praxis häufig Behauptungen aufgestellt und Kausalitäten als bewiesen bewertet, obwohl diese Zusammenhänge keiner kritischen Überprüfung standhalten könnten.
Es ist wichtig, immer einen kritischen Blick auf vermeintliche Effekte zu werfen und nicht einfach davon auszugehen, dass ein Automatismus bewiesen wurde, nur weil eine Korrelation statistisch festgestellt werden konnte. Der Effekt sollte stets hinterfragt werden, damit Fehlinterpretationen nicht dazu führen, dass falsche Handlungsempfehlungen gegeben werden. Unbeachtete Heterogenitäten, Messfehler aber auch umgekehrte Kausalitäten können für die nur scheinbar bestehende Kausalität verantwortlich sein. Diese drei Quellen von Endogenität müssen zunächst ausgeschlossen werden, damit davon ausgegangen werden kann, dass die Korrelation nicht aufgrund einer Störgröße, sondern aufgrund einer tatsächlichen, quantifizierbaren Kausalität festgestellt wurde. Darüber hinaus muss die Bedingung erfüllt sein, dass die Stichprobe die Grundgesamtheit korrekt abbildet also repräsentativ ist.
Fehlende Einbeziehung unbeobachteter Einflussfaktoren
Es gibt Einflussfaktoren, die nicht messbar sind und deshalb auch nicht erhoben werden. Diese Faktoren können jedoch durchaus Einfluss auf die kontrollierbaren Faktoren ausüben und somit deren Parameter verzerren. Dann wird beispielsweise ein gemessener Effekt einer beobachteten Größe zugeschrieben, obwohl er von anderen Faktoren verursacht wurde.
Das bekannteste Beispiel für eine derartige Verzerrung ist die Lohngleichung, genauer gesagt, die Intention festzustellen, welche Einflussfaktoren die Höhe des Lohns bedingen. Neben messbaren Faktoren wie der Qualifikation, dem Alter oder der Berufserfahrung beeinflussen auch nicht messbare Faktoren die Höhe des Lohns. Besonders das individuell unterschiedliche Interesse des Arbeitnehmers am lukrativen Erwerb kann kaum quantifiziert und gemessen werden, hat jedoch unbestreitbar Einfluss auf die Höhe der Entlohnung.
Derartige Probleme entstehen auch bei der Datenanalyse im Unternehmen, und die Herausforderung besteht darin, dass es keinen statistischen Test gibt, mit dem der Einfluss von unbeobachteten Faktoren gemessen werden kann. Aus diesem Grund müssen die Mitarbeiter, die mit der Interpretation der Ergebnisse von Datenanalysen betraut wurden, über ein vertieftes Verständnis des Analyseproblems verfügen. Nur dann ist es möglich, Hypothesen zu der Frage zu formulieren, welche unbeobachteten Größen das Ergebnis verfälschen. Das kann mit smarten Schätzdesigns oder fortschrittlichen Analyse Tools durchgeführt werden.
Nichtbeachtung der Selektionsverzerrung
Immer wenn nicht für jedes Individuum Beobachtungen vorliegen oder wenn Beobachtungen von der Datenanalyse ausgeschlossen wurden, kommt es zu Selektionsverzerrungen, denn dann liegen die Grundvoraussetzungen eines statistischen Hypothesentests nicht vor. Diese Grundvoraussetzungen besagen, dass die Stichprobe so zusammengestellt wurde, dass die Grundgesamtheit repräsentativ abgebildet ist. In der Praxis kann diese Forderung jedoch nicht immer erfüllt werden, weil Merkmale nur für ein Gruppe festgestellt werden können, für andere ebenso relevante Gruppen jedoch nicht. Jede Selektion führt zu einer Verzerrung der Ergebnisse statistischer Datenanalysen.
Besteht beispielsweise die Aufgabe der Datenanalyse darin, die Effekte von gesundheitsfördernden Maßnahmen in einem großen Unternehmen durch eine Mitarbeiterbefragung zu überprüfen, kann dies nicht durch eine freiwillige Teilnahme der Mitarbeiter erfolgen. Es muss die Frage beantwortet werden, worin sich die Gruppe der freiwilligen Probanden von denjenigen Mitarbeitern, die nicht freiwillig teilnehmen, unterscheidet.
Wird bei der Interpretation der Analyseergebnisse nicht berücksichtigt, dass die Stichprobe andere Merkmale aufweist als die Grundgesamtheit, besteht die Gefahr, dass Effekte über- oder unterschätzt werden. Das hat zur Folge, dass Generalisierungen vorgenommen werden, die falsch sind, weil die Stichprobe, aufgrund derer sie vermeintlich festgestellt wurden, nicht repräsentativ war. Als Folge werden dann falsche Handlungsempfehlungen gegeben. Ziel der Digitalisierung und der Analyse von Massendaten ist jedoch gerade die Verbesserung von Entscheidungsgrundlagen aufgrund datenbasierter Informationen.
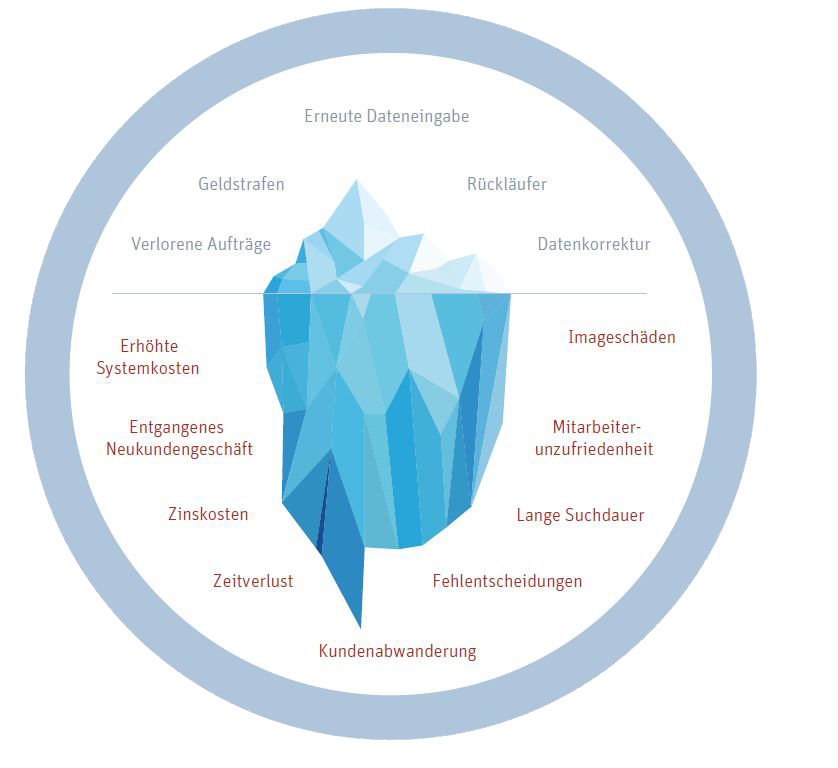
Infografik Datenanalyse: Folgen mangelnder Datenqualität (DQ) (#3)
Überanpassung: Fehleinschätzung des Informationsgehalts von Datenbeständen
Eine sogenannte Überanpassung ist immer dann gegeben, wenn der Analyst den Informationsgehalt der Daten überschätzt. Das geschieht durch das Überstrapazieren des Modells, sodass die Kontrollvariablen nicht nur die Zielgrößen erklären, sondern auch die Zufallsfehler. Es werden im Vergleich zur Anzahl der Beobachtungen zu viele Regressoren ins Modell aufgenommen. Regressoren dürfen nicht einfach als unabhängige Variablen betrachtet werden. Resultat sind dann Schätzergebnisse, die zu weit vom wahren Wert entfernt liegen. Business Analytics Tools könnten Hilfestellung geben. Mit verschiedenen Validierungsmethoden kann nachgewiesen werden, ob der Analyst den Informationsgehalt des Datenbestands korrekt eingeschätzt hat. Dazu werden beispielsweise die korrelierten Regressoren zueinander in Beziehung gesetzt.
Fehlende Datenpunkte führen zu verzerrten Ergebnissen der Datenanalyse
Wenn Datenpunkte fehlen, folgt daraus in der Praxis der Datenanalyse meist, dass diese Beobachtungen nicht berücksichtigt werden. Bei einer derartigen Vorgehensweise wird die Frage vernachlässigt, warum diese Datenpunkte fehlen. Kann das Fehlen als zufällig beurteilt werden, ist kein Einfluss auf das Messergebnis zu befürchten und der Ausschluss der entsprechenden Beobachtungen ist korrekt. Es besteht aber auch durchaus die Möglichkeit, dass das Fehlen nicht zufällig ist, sondern dass die Datenpunkte systematisch fehlen. Das ist beispielsweise der Fall, wenn Personen mit bestimmten Merkmalen Daten bewusst zurückhalten.
Für Analysten besteht in diesem Fall die Herausforderung darin, die gesamte Verteilung zu ermitteln. Immer wenn keine eindeutige Klarheit darüber besteht, ob Datenpunkte zufällig oder systematisch fehlen, sollte der Analyst versuchen, das Problem zu lösen, indem er die Daten imputiert. Bei der Imputation werden fehlende Daten, sogenannte Antwortausfälle, in der Datenmatrix vervollständigt, um die Verzerrungen, die von einem systematischen Fehlen verursacht werden, zu minimieren. Zu diesen Zweck sollte der Analyst alle Informationen beschaffen, die ein sachgemäßes Imputieren der Daten erlauben.
Der korrekte Umgang mit Ausreißern
Die Business Intelligence Tools, mit denen die Datenanalysen durchgeführt werden, verfügen über standardisierte Verfahren, mit denen Ausreißer zunächst identifiziert und anschließend aus dem Datensatz entfernt werden. Diese vereinfachte Vorgehensweise ist nicht immer zielführend, denn oft lohnt es sich, die Ausreißer näher zu betrachten. Es ist nur sinnvoll, Datenpunkte auszuschließen, die sich durch Eingabefehler oder bewusste Falschmeldungen erklären lassen. Ansonsten ist es zielführend, genauer zu analysieren, wie sich die Ausreißer erklären lassen, denn alle legitimen Datenpunkte sind echte Werte und müssen deshalb auch in die Interpretation der Ergebnisse einbezogen werden.
Ausreißer sind Teil der Grundgesamtheit und tragen deshalb zur Generierung des Erkenntnisgewinns bei. Es muss jedoch beachtet werden, dass die Einbeziehung von Ausreißern auch Probleme nach sich ziehen kann. Dies ist immer dann der Fall, wenn durch die Ausreißer Zusammenhänge identifiziert werden, die für die restliche Grundgesamtheit nicht zutreffen. Mit einer Transformation der Daten oder der Anwendung robuster Schätzverfahren, wird es möglich, Ausreißer einerseits nicht zu vernachlässigen und andererseits die unerwünschten Effekte zu minimieren.
Abwägen von Spezifizierung und Modellierung
Oft werden bei der Datenanalyse zu umfangreiche Modelle zugrunde gelegt, obwohl einfachere Modelle Zusammenhänge eventuell besser abbilden. Vor der Generierung eines komplexen Modells sollte zunächst die Spezifikation des Modellansatzes betrachtet werden. Anstatt ein allzu komplexes Modell aufzustellen, ist es in vielen Fällen sinnvoller, durch die Einbeziehung verbesserter Variablen oder Interaktionen sowie nicht-linearen Effekten die gewünschten Erkenntnisfortschritte zu erzielen. Erst wenn diese drei Möglichkeiten ausgereizt sind, ist es lohnenswert, die Komplexität des Modells zu erhöhen.
Generell gilt, das ein einfaches Modell leichter zu kontrollieren ist und die Datenanalyse eindeutigere Ergebnisse erbringt. Mit Sensitivitätsanalysen können die gewählten Spezifikationen unterstützt werden. Werden Veränderungen an der Definition der Variablen oder der Selektion von Daten vorgenommen, ist es wichtig, dies einerseits zu testen und andererseits nachvollziehbar zu dokumentieren. Stellt der Analyst fest, dass die Annahmen des einfachen Modells nicht zutreffen, ist es nötig, zu einem komplexeren Modell zu wechseln, damit valide Ergebnisse produziert werden können. Vor der Anwendung eines statistischen Modells müssen dessen Voraussetzungen kritisch hinterfragt und das Modell gegebenenfalls modifiziert werden.
Nicht zielgerichtetes Sammeln von Massendaten
Viele Unternehmen sammeln Daten, als ob mit einer größeren Anzahl von Datenquellen auch automatisch die Generierung von relevanten Informationen verbunden ist. Die Möglichkeiten, immer noch mehr Daten zu sammeln, sind nahezu unbegrenzt und wachsen exponentiell. Mittlerweile wird die weltweite Datenmenge in Zettabytes gemessen, also in Zahlen mit 21 Nullstellen, mit denen man jedes Element, das auf der Erde existiert, zählen könnte. Die Digitalisierung schreitet in den Unternehmen aber auch in der Gesellschaft unerbittlich voran und das Ziel, alle analogen Informationen als digitale 0-1-Codes abzuspeichern, rückt in greifbarer Nähe. Das Internet of Things ist längst keine Utopie mehr, sondern in vielen Bereichen bereits Realität.
Aus dem Vorhandensein von Massendaten, die von Unternehmen eifrig gesammelt werden, folgt jedoch nicht unbedingt, dass diese auch alle für das Unternehmen relevant und von Interesse für die Entscheidungsfindung sind. Vielen Firmen fehlen auch schlicht die Kenntnisse, wie man Big Data effektiv nutzen kann. Aus dem Material der Rohdaten lassen sich allein keine Empfehlungen ableiten. Der Nutzwert von Daten, die in komplexen Datenbanksystemen abgespeichert werden oder in Tabellenkalkulationen kopiert werden, ist gering, manchmal sogar nicht vorhanden. Aus diesem Grund sollten die Unternehmen die Einbeziehung neuer Datenquellen kritisch hinterfragen, damit die Datenmodelle nicht zu komplex werden und dadurch die Datenanalyse sowie die anschließende Interpretation der Ergebnisse erschwert werden.
Probleme beim Kategorisieren und Aufbereiten von Daten
Viele Unternehmen gehen wie folgt vor: Zunächst werden die Datenberge mit entsprechenden Business Intelligence Tools bereinigt, bearbeitet und schließlich kategorisiert. Es ist jedoch wichtig, schon in der Phase der Datenbereinigung und -strukturierung darauf zu achten, dass die Daten Antworten auf die Fragen, die sich im Unternehmen stellen, geben können. Oft wandelt sich das Big Data Projekt, das dem Management bei der Fundierung seiner Entscheidungen helfen soll, zum reinen IT-Projekt. Fehlt die Unterstützung von Seiten der Geschäftsnutzer, ist nicht zu erwarten, dass die Potentiale von Big Data ausgeschöpft werden können.
Fehlende Planung erschwert die Umsetzung von Big Data Projekten
Mit dem ungeplanten, weitgehend ziellosen, Sammeln von Daten kann kein Mehrwert erzeugt werden. Die Planung des Umgangs mit riesigen Datenmengen ist jedoch genauso wichtig wie die Planung jedes anderen Projekts. Es ist nötig, die einzelnen Schritte des Prozesses zu analysieren und an den Unternehmenszielen auszurichten. Am Beginn des Prozesses sollte eine strategische Businessfrage stehen. Davon ausgehend wird festgelegt, welche Daten zur Beantwortung dieser Frage benötigt werden. Nach der Einbeziehung der adäquaten Datenquellen muss vor der Durchführung einer Datenanalyse die Qualität der Daten sichergestellt werden. Auf diese Weise wird es möglich, aus wertlosen Daten wertvolle Informationen zu extrahieren.
Unternehmensinterne Prozesse sind nicht auf Big Data abgestimmt
Mangelt es an der Festlegung von Zuständigkeiten und sind die Prozesse im Unternehmen nicht auf die digitale Transformation abgestimmt, fehlt es an den grundlegenden Voraussetzungen, damit die Datenanalyse erfolgreich durchgeführt werden kann. Wenn die Unternehmensprozesse nicht auf Komplexität ausgerichtet sind, werden Big Data Projekte unweigerlich scheitern. Oft werden innovative neue Technologien für die Datenverarbeitung eingesetzt, ohne die Mitarbeiter entsprechend durch Qualifikationsmaßnahmen auf den Umgang mit den Software Anwendungen vorzubereiten. Mit einer frühzeitigen Abstimmung zwischen der Unternehmensführung und dem IT-Bereich können diese Probleme beseitigt werden.
Fehlen von klaren Zielvorgaben
Datenanalyse ohne Zielvorgabe ist sinnlos und wird nicht dazu führen, wertvolle Informationen zu generieren. Damit eine unternehmensweite Sensibilisierung für die Anforderungen der Digitalisierung erreicht wird, muss den Mitarbeitern auch vermittelt werden, welche Ziele mit Datenanalysen im Rahmen von Big Data verfolgt werden. Ein Ziel kann beispielsweise sein, den Marktanteil in einem bestimmten Land zu erhöhen. Daraus ergibt sich zunächst die Frage, welche Informationen für die Erreichung dieses Ziels benötigt werden.
Die vorliegenden Daten werden nach relevanten Informationen durchsucht und außerdem wird entschieden, ob neue Datenquellen in die Datenanalyse aufgenommen werden sollten. Entscheidet man sich für die Einbeziehung weiterer Datenquellen, ist dafür zu sorgen, dass diese mit den bestehenden Datensätzen harmonisiert werden, damit ein konsistenter Datenbestand erzeugt wird.
Für viele Unternehmen ist die Formulierung von Zielen der Datenanalyse jedoch nicht leicht und daraus resultieren auch Unsicherheiten darüber, welche BI Tools für die Datenanalyse eingesetzt und welche Datenquellen verwendet werden sollen. Deswegen sollten zunächst die Fragen beantwortet werden, welche Daten mit dem Kundenerlebnis korrelieren und wie die Produktion datenbasiert unterstützt sowie Lieferketten optimiert werden können.
Mit anderen Worten: Es ist sehr entscheidend zu erkennen, welche Daten das Business vorantreiben, und basierend auf diesem Wissen ein passendes System für die gezielte Datenanalyse zu konfigurieren und zu implementieren. Dabei ist es wichtiger, die Key Performance Indicators (KPIs) und die Businesspläne des Unternehmens zu berücksichtigen, als den Datenbestand lediglich aus technologischer Perspektive zu beurteilen. Datenanalyse ist kein Selbstzweck, sondern sollte sich immer an der Frage ausrichten, was sie zur Erhöhung der Wettbewerbsfähigkeit beitragen kann.
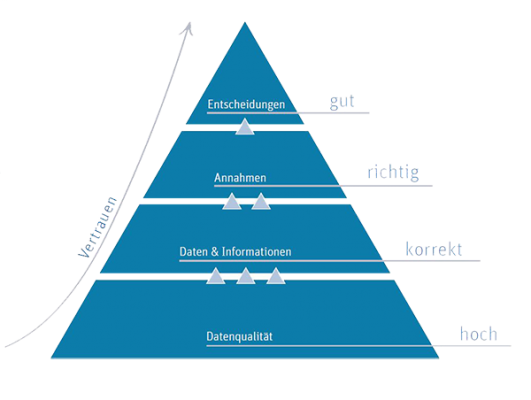
Infografik Datenanalyse: Zusammenhang Datenqualität (DQ-und-Entscheidungen (#4)
Erfolgsfaktor Mitarbeiter
Digitalisierung bedeutet keinesfalls, dass der Faktor Mensch in den Unternehmen unwichtig wird. Im Gegenteil, die beste Datenanalyse ist sinnlos, wenn die Ergebnisse nicht korrekt interpretiert werden. Es ist leider nicht immer der Fall, dass die Mitarbeiter im IT-Bereich, die sich hervorragend mit den modernen Informationstechnologien auskennen, auch im Bereich der Dateninterpretation die besten Ergebnisse erzielen.
Andererseits sind Mitarbeiter, die über das entsprechende Verständnis der wirtschaftlichen Zusammenhänge verfügen, oft nicht ausreichend im Bereich IT qualifiziert. Da beide Qualifikationen benötigt werden, damit Big Data gelingen kann, ist die Qualifizierung der Mitarbeiter sehr wichtig. Im Management sollten zumindest Grundkenntnisse über die Zusammenhänge moderner Datenanalysen vorhanden sein. Die IT-Experten profitieren demgegenüber von Weiterbildungsmaßnahmen in Hinsicht auf die wichtigen Businessfragen, denen sich das Unternehmen im globalisierten Wettbewerb stellen muss.
Der Mitarbeiterqualifikation sollte deshalb genauso viel Aufmerksamkeit geschenkt werden wie der Investition in Business Intelligence Technologien. Ziel sollte es sein, dass die Analysten der IT-Abteilung dem Management die Informationen, die sich in den Datenbergen verstecken, näherbringen. Andererseits sollten die Mitarbeiter anderer Fachabteilungen in der Lage sein, Ad hoc Analysen anlass- und themenbezogen im Self-Service durchzuführen, damit das gesamte System des Datenmanagements über eine ausreichende Flexibilität verfügt. Im Tagesgeschäft ist oft schnelles Handeln erforderlich, sodass es notwendig ist, unmittelbar dort, wo die Fragen auftreten, Datenanalysen durchzuführen. Die IT-Abteilung hat dann Kapazitäten frei, um die Infrastruktur der Datenanalyse zu pflegen und zu optimieren.
Vermeidung von Fehlern bei der Datenanalyse ebnet den Weg zu Big Data
Auch wenn noch Hindernisse der digitalen Transformation im Weg stehen, ist die Entwicklung hin zur datenbasierten Unternehmensführung unumkehrbar. Weltweit ist alle drei Jahre mit einer Verdoppelung der Daten zu rechnen, denn digitale Plattformen, Sensortechnologien und nicht zuletzt Milliarden von Smartphones produzieren täglich massenhaft Daten. Gleichzeitig sinken die Kosten für die Speicherung der Massendaten kontinuierlich und das eröffnet den Firmen riesige Potentiale. Mit den modernen Technologien ist es möglich, die Vision einer informationsgestützten Entscheidungsfindung zu realisieren. Es erhöht die Qualität von unternehmerischen Entscheidungen, wenn diese nicht aufgrund diffuser Bauchgefühle getroffen werden, sondern aufgrund von handfesten Informationen.
Diese Informationen zu generieren, ist mit Hilfe der innovativen Informationstechnologien möglich. Effiziente Speichermedien und leistungsstarke Business Analytics versetzen Unternehmen in die Lage, riesige Datenmengen zielgerichtet auszuwerten und somit die Kausalzusammenhänge und Trends zu erkennen. Unternehmen, die sich bemühen, mit der Entwicklung Schritt zu halten, erarbeiten sich große Wettbewerbsvorteile. Sie sind fähig, Chancen schnell zu erkennen und zu ergreifen und können sich außerdem vor dem Eintritt ungünstiger Szenarien durch ein entsprechendes datenbasiertes Risikomanagement schützen.
Trotz dieser unbestreitbaren Vorteile dürfen Unternehmen die Fehlerquellen bei der Datenanalyse nicht vernachlässigen. Werden aufgrund falscher statistischer Annahmen Korrelationen hergestellt und daraus Kausalitäten abgeleitet, wo dies nicht angebracht ist, sind die auf diesen Annahmen basierenden Entscheidungen mit hoher Wahrscheinlichkeit falsch. Anwender sollten auch beachten, dass sich ab einer bestimmten Anzahl von Analysevorgängen automatisch Zusammenhänge zwischen den Daten ergeben. Moderne Analytics Anwendungen helfen den Usern dabei, diese Scheinzusammenhänge zu erkennen. Oft sind qualifizierte Mitarbeiter der eigentliche Engpass bei der Umsetzung einer Strategie der Digitalisierung. Jedes Unternehmen benötigt Experten, die aus den Ergebnissen der Datenanalyse zunächst korrekte Schlussfolgerungen ableiten und darüber hinaus auch in der Lage sind, diese in Geschäftsanwendungen umzusetzen.
Schon bei der Sammlung und Konsolidierung der Daten sollte darauf geachtet werden, dass eine ausreichende Qualität der Daten gewährleistet ist. Fehler, die im Verlauf der Daten-Aggregation entstehen, führen zu falschen Ergebnissen und sind nur sehr schwer nachvollziehbar. Nur wenn die Basisdaten im Hinblick auf Genauigkeit, Transparenz und Integrität hochwertig sind, sind die Voraussetzungen für die Datenanalyse erfüllt. Die wenigsten Unternehmen haben das Potential, dass die Big Data Technologien bieten, bereits vollständig ausgeschöpft.
Doch schon jetzt ist es ein Merkmal der wertvollsten Unternehmen weltweit, dass sie signifikant stärker die intelligente Datennutzung vorangetrieben haben und in diesem Bereich Vorreiter sind. Um nicht den Anschluss zu verlieren, sollten Unternehmen, bei denen bisher Digitalisierung noch nicht als ein Hauptthema auf der Agenda steht, dieses ändern und den Fokus auf die digitale Transformation richten.
Bildnachweis: © humanIT #1 + #2 + #3 + #4, shutterstock – Titelbild NicoElNino











