


Der Unternehmenserfolg hängt wesentlich von der Datenqualität ab. Eine mangelhafte Qualität verlangsamt nicht nur eine Datenanalyse, sondern auch viele andere Prozesse und führt zu unnötigen Friktionen. Für operative und strategische Entscheidungen benötigt das Management korrekte und zuverlässige Informationen. Mit den im Folgenden vorgestellten 10 Tipps gelingt es Unternehmen, die Datenqualität durch Data Cleansing effektiv zu verbessern.
Clean Data: Datenbereinigung steigert die Datenqualität
Daten bilden die Realität ab. Wie gut dies gelingt, hängt von der Datenqualität ab. Nur wenn diese hoch ist, kann das Management auf die Datenbasis vertrauen und zeitnah korrekte Entscheidungen treffen. Es ist aufwendiger, Fehler zu suchen und zu korrigieren, als von Anfang an darauf zu achten, dass die Datenspeicherung korrekt abläuft. Mit den im Weiteren vorgestellten zehn Tipps wird es leichter, eine hohe Datenqualität zu erreichen, die sich durch Aktualität, Zuverlässigkeit und adäquaten Detaillierungsgrad auszeichnet.
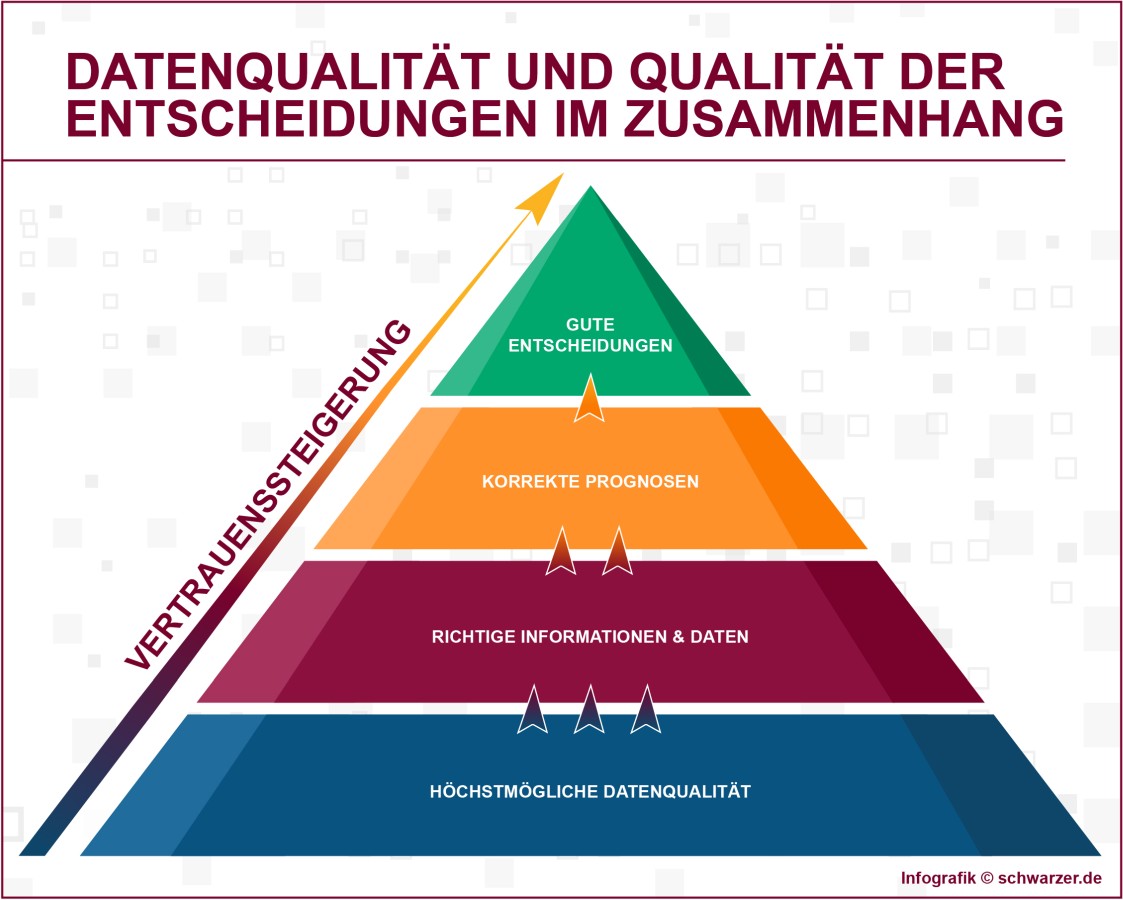
Infografik: Datenqualität und Entscheidungen im Zusammenhang
Die Datenbereinigung (Data Cleansing) ist der Prozess der Korrektur oder des Entfernens von Informationen aus Datenbanken. Das wird immer dann notwendig, wenn die Daten fehlerhaft, falsch formatiert, unvollständig oder doppelt abgespeichert wurden. Mit Hilfe von Business Analytics Tools kann der Datenbestand hinsichtlich vorher festgelegter Kriterien systematisch durchforstet werden.
Eine wichtige Voraussetzung für das Gelingen ist jedoch, den Maßnahmen einen organisatorischen Rahmen zu geben, in welchem Zuständigkeiten und Prozesse einheitlich definiert werden. Im Data Governance wird ein Datenqualitätsteam mit der Aufgabe des Daten-Profiling betraut. Außerdem werden dort die Regeln für Datenqualität definiert und auf Basis erster Messungen Aussagen zur Datenqualität getroffen. Zusammen mit einem Data Owner, der für die Datenqualität verantwortlich ist, wird eine Bewertung der Situation vorgenommen. Der Data Owner erhält hinsichtlich der Datenqualität ein Briefing vom Datenqualitätsteam und führt einerseits Korrekturen durch.
Andererseits erteilt er Aufträge an das Qualitätsteam hinsichtlich erforderlicher Anpassungen oder Neuerungen der Qualitätsregeln. Direkte Profiteure einer hohen Datenqualität sind die Data User, die täglich mit dem zur Verfügung gestellten Datenmaterial arbeiten und ihrerseits ebenfalls Anforderungen an die Datenqualität definieren. Die Data User stellen im operativen Geschäft als Erste Mängel fest und können auch spezielle Messungen beantragen. Damit Rollenkonflikte vermieden werden, sollte das Datenqualitätsteam von anderen Aufgaben freigestellt werden und sich ausschließlich um die Sicherstellung einer hohen Datenqualität kümmern.
Sind die organisatorischen Voraussetzungen gegeben, wird es mit den folgenden zehn Tipps gelingen, den Anspruch an eine hohe Datenqualität umzusetzen und dauerhaft dafür zu sorgen, dass das Datenqualitätsmanagement reibungslos in den Unternehmensalltag integriert wird. Auf diese Weise wird verhindert, dass ad hoc-Aktionen notwendig werden, weil der Bereich der Informationsqualität im Tagesgeschäft vernachlässigt wurde und plötzlich ein akuter Handlungsbedarf entsteht.
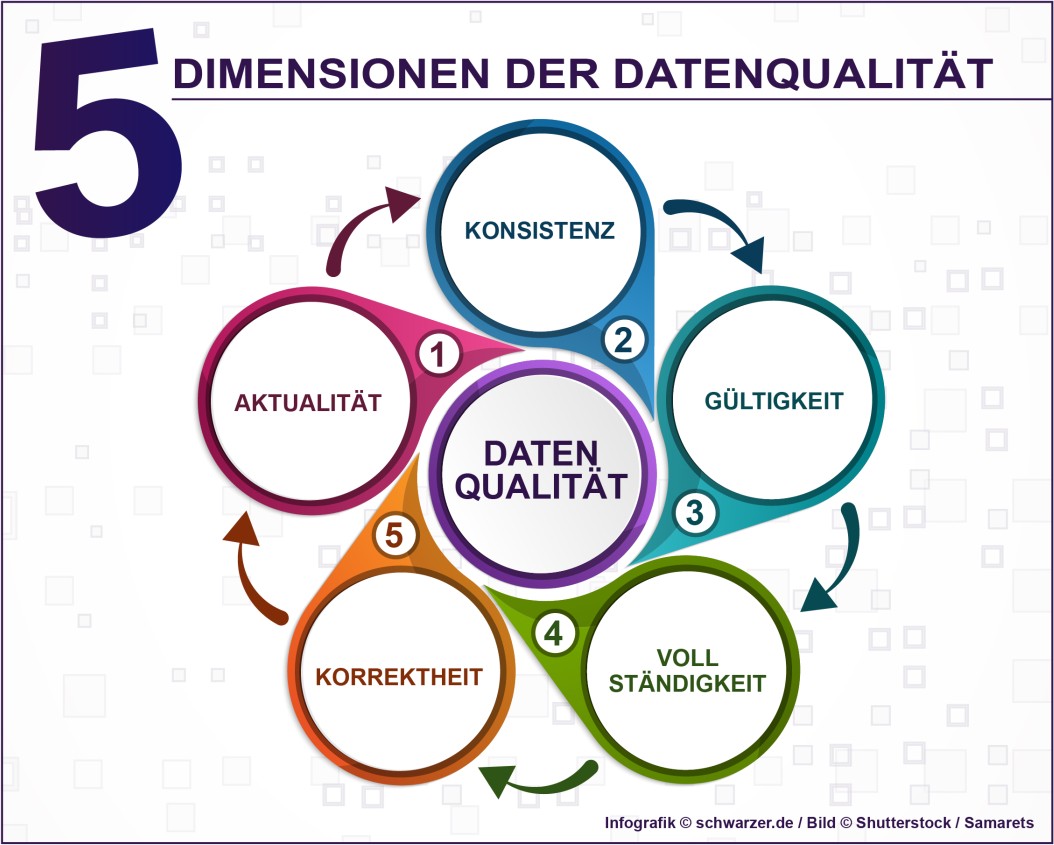
Infografik: Die 5 Dimensionen der Datenqualität
Verbesserung des Unternehmenserfolgs durch Clean Data:
Eine unzureichende Datenqualität tangiert verschiedene erfolgskritische Bereiche:
- Doppelungen von Adresseinträgen verhindern Cross-Selling
- schlechte Adressqualität erschwert Mailing-Aktionen
- Produktivität des Vertriebs leidet durch fehlerhafte Adressen
- Lagerprodukte werden doppelt bestellt
Diese und weitere Probleme können durch eine Strategie zur Steigerung der Informationsqualität behoben werden.
Die folgenden Tipps erleichtern die Umsetzung dieser Strategie im Unternehmensalltag:
Tipp 1: Sensibilisierung aller Ebenen für das Thema Datenqualität
 Business Intelligence kann ohne Clean Data nicht funktionieren. Erst wenn diese Einsicht im Management verankert und somit gelebt wird, hat Clean Data eine Chance. Ziel ist die umfassende Sensibilisierung der Mitarbeiter für das Thema Informationsqualität. Es ist sinnvoll, konkrete Ziele zu formulieren und mit einem Datenqualitätsmanagement konsequent zu verfolgen.
Business Intelligence kann ohne Clean Data nicht funktionieren. Erst wenn diese Einsicht im Management verankert und somit gelebt wird, hat Clean Data eine Chance. Ziel ist die umfassende Sensibilisierung der Mitarbeiter für das Thema Informationsqualität. Es ist sinnvoll, konkrete Ziele zu formulieren und mit einem Datenqualitätsmanagement konsequent zu verfolgen.
Ein mögliches Ziel ist die Verbesserung der Kundenbeziehungen. Es ist nachvollziehbar, dass nur mit einer redundanzfreien Speicherung der Kundendaten eine aktuelle Kundendatenbank erstellt werden kann, auf deren Basis eine optimale Betreuung der Kunden erfolgt.
Bis hinunter auf die Ebene der Lagerarbeiter muss allen Mitarbeitern bewusst werden, dass bereits minimale Ungenauigkeiten bei der Datenspeicherung weitreichende Folgen haben. Kosten steigen und die Wettbewerbsfähigkeit des eigenen Unternehmens sinkt. Datenqualität und Business Intelligence beginnen also dort, wo die Daten entstehen, auf der operativen Ebene zum Beispiel beim Logistiker.
Tipp 2: Beurteilung der Datenqualität durch Analyse der Datenbestände
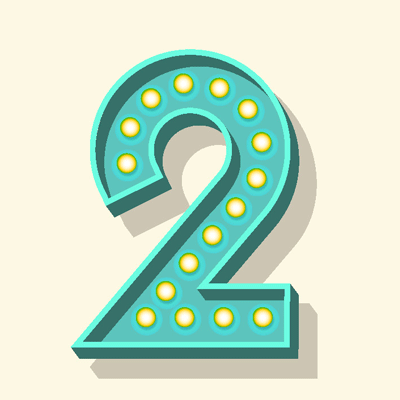 Bevor konkrete Maßnahmen zur Datenbereinigung geplant und durchgeführt werden, ist es notwendig festzustellen, wie es um die Informationsqualität aktuell bestellt ist. Mit Hilfe innovativer Analysetools und -verfahren wird zunächst der Ist-Zustand der Daten erfasst und sorgfältig dokumentiert.
Bevor konkrete Maßnahmen zur Datenbereinigung geplant und durchgeführt werden, ist es notwendig festzustellen, wie es um die Informationsqualität aktuell bestellt ist. Mit Hilfe innovativer Analysetools und -verfahren wird zunächst der Ist-Zustand der Daten erfasst und sorgfältig dokumentiert.
Eine Analytics Software stellt dabei die Probleme und Fehlerhäufigkeiten fest. In diesem Schritt erkennt man ohne großen Aufwand Redundanzen bei den Stammdaten. Darüber hinaus werden unvollständige Datensätze sowie widersprüchliche Kausalitäten entdeckt und fehlerhafte Datensätze identifiziert.
Am Ende dieser ersten Bestandsaufnahme steht in der Regel die Erkenntnis, dass 90 bis 95 Prozent aller Daten korrekt sind. Jetzt kommt es darauf an, geeignete Maßnahmen zu ergreifen, um die Fehler zu eliminieren.
Tipp 3: Definition von Regeln für Relevanz und Korrektheit
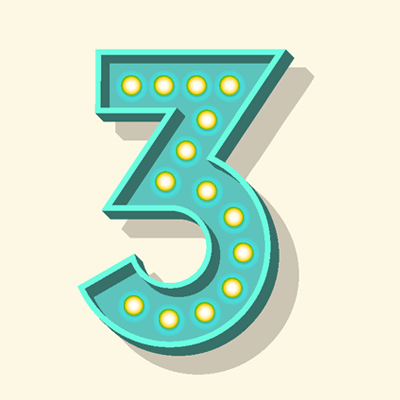 In diesem Schritt wird verbindlich festgelegt, wie ein korrekter Datensatz definiert ist und welche Informationen überhaupt erhoben werden sollen, weil sie für das Unternehmen relevant sind.
In diesem Schritt wird verbindlich festgelegt, wie ein korrekter Datensatz definiert ist und welche Informationen überhaupt erhoben werden sollen, weil sie für das Unternehmen relevant sind.
Dabei stehen ganz praktische Fragestellungen im Fokus: Soll im Datensatz eines Kunden dessen Mailadresse vorhanden sein oder ist die Telefonnummer ausreichend? Wurde Einigkeit über die notwendigen Inhalte erzielt, wird mit einem unternehmensweiten Glossar dafür gesorgt, die Richtlinien zu kommunizieren. In diesem Glossar befindet sich eine detaillierte Beschreibung des Inhalts und der Metrik der Datensätze.
Zum einen können auf diese Weise alle Mitarbeiter die Qualitätskriterien nachvollziehen und zum anderen bilden diese Vorgaben die Basis für die Feststellung von Abweichungen und somit für die darauf aufbauende Datenbereinigung.
Tipp 4: Datenbereinigung vornehmen und regelmäßig wiederholen
 Nach der vorangegangenen Definition des Ist-Zustands und der Feststellung von Abweichungen kann mit der eigentlichen Datenbereinigung, dem Data Cleansing, begonnen werden. Es ist sinnvoll, dies nicht als einmalige Aktion zu verstehen, sondern eine Strategie für künftiges Vorgehen bei der Datenpflege zu implementieren.
Nach der vorangegangenen Definition des Ist-Zustands und der Feststellung von Abweichungen kann mit der eigentlichen Datenbereinigung, dem Data Cleansing, begonnen werden. Es ist sinnvoll, dies nicht als einmalige Aktion zu verstehen, sondern eine Strategie für künftiges Vorgehen bei der Datenpflege zu implementieren.
Am Anfang wird dabei ein angestrebter Qualitätslevel definiert und auch festgelegt, wie schnell dieser Level erreicht werden muss. Datenqualitätssicherung ist eine unternehmerische Daueraufgabe, frei nach dem Motto „keep it clean“. Das wird durch die Festlegung verbindlicher Prozesse für diesen Vorgang erreicht.
Die Kontrolle der Qualität und die sich anschließende Datenbereinigung sind in regelmäßigen Abständen zu wiederholen. Mit einer Analytics Software werden diese Aufgaben problemlos in den Unternehmensalltag integriert.
Tipp 5: Eindeutige Kompetenzzuweisungen sichern den Erfolg des Data Cleansing
 Durch eine Übertragung von Kompetenzen in den einzelnen Fachabteilungen und auch unternehmensweit wird sichergestellt, dass die Aufgabe des Data Cleansing gemäß ihrer Bedeutung wahrgenommen und durchgeführt wird. Es erfolgt eine eindeutige Festlegung, wer die Daten einpflegt und wer für die Korrektur festgestellter Fehler zuständig ist.
Durch eine Übertragung von Kompetenzen in den einzelnen Fachabteilungen und auch unternehmensweit wird sichergestellt, dass die Aufgabe des Data Cleansing gemäß ihrer Bedeutung wahrgenommen und durchgeführt wird. Es erfolgt eine eindeutige Festlegung, wer die Daten einpflegt und wer für die Korrektur festgestellter Fehler zuständig ist.
Damit wird verhindert, dass diese Aufgabe im Sand verläuft, weil sich letztlich niemand ernsthaft dafür verantwortlich fühlt. Außerdem wird auf diese Weise vermieden, dass in parallelen Datenbanken redundante Datensätze abgespeichert werden. Laufen verschiedene Datenbanken im Unternehmen nebeneinander her, müssen diese permanent synchronisiert und um Redundanzen bereinigt werden.
Das ist ein vermeidbarer Aufwand, der den reibungslosen Ablauf der Prozesse behindert. Besonders wenn mehrere Abteilungen in eine Aufgabe involviert sind, ist es sehr wichtig sicherzustellen, dass beispielsweise durch eine einheitliche Vergabe von Auftragsnummern möglichen Unstimmigkeiten schon im Vorfeld begegnet wird. Die mit der Datenpflege beauftragten Mitarbeiter benötigen Handlungsspielräume und eine ebenfalls festgelegte, institutionalisierte Möglichkeit, dem Management Probleme und Verbesserungsbedarfe zu schildern.
Tipp 6: Qualitätssicherung beginnt mit der Datenerfassung
 Wenn bereits bei der Datenerfassung auf Qualität geachtet wird, lassen sich viele Fehlerquellen von vornherein ausschalten. Das ist mit Sicherheit effektiver, als im Nachhinein mühevoll nach Fehlern zu suchen. Aus diesem Grund sollten die Eingabemasken für die Datenerfassung so einfach und selbsterklärend wie möglich gestaltet sein, um den Anwendern ihre Aufgaben zu erleichtern.
Wenn bereits bei der Datenerfassung auf Qualität geachtet wird, lassen sich viele Fehlerquellen von vornherein ausschalten. Das ist mit Sicherheit effektiver, als im Nachhinein mühevoll nach Fehlern zu suchen. Aus diesem Grund sollten die Eingabemasken für die Datenerfassung so einfach und selbsterklärend wie möglich gestaltet sein, um den Anwendern ihre Aufgaben zu erleichtern.
Innovative ERP-Systeme führen eigenständig Plausibilitätsüberprüfungen durch und checken darüber hinaus auch sofort die Vollständigkeit der Datensätze. Werden vom System Unstimmigkeiten festgestellt, wird der Nutzer mit einer Warnfunktion informiert und kann umgehend die Eingabe korrigieren. Auf diese Weise erreicht man die Minimierung von Flüchtigkeitsfehlern, die auch einem sorgfältig arbeitenden Mitarbeiter unterlaufen können.
Tipp 7: Verbindliche und eindeutige Vorgaben für die Datenpflege
 Eine wichtige Anforderung an die Datenqualität besteht darin, doppeltes Speichern an verschiedenen Orten zu verhindern. Werden beispielsweise eindeutige Merkmale und Produktbezeichnungen für jeden Artikel definiert, wird das Problem der doppelten Speicherung wesentlich reduziert.
Eine wichtige Anforderung an die Datenqualität besteht darin, doppeltes Speichern an verschiedenen Orten zu verhindern. Werden beispielsweise eindeutige Merkmale und Produktbezeichnungen für jeden Artikel definiert, wird das Problem der doppelten Speicherung wesentlich reduziert.
Dabei gilt wie in jedem Bereich der Informationsverarbeitung: Je genauer die Vorgaben am Anfang definiert werden, desto geringer ist das Fehlerpotential. Ein wichtiger Punkt ist in diesem Zusammenhang das Vermeiden von Abkürzungen, denn diese können zu Missverständnissen führen.
Es ist außerdem wichtig, die Nutzergewohnheiten zu berücksichtigen und die Vorgaben der Key-User einzubeziehen. Auch mit dieser Vorgehensweise kann man Fehlerquellen gezielt ausschalten.
Tipp 8: Definition automatisierter Workflows bei der Datenerfassung

Durch integrierte Abläufe fließen bereits viele Daten automatisch ins System ein, beispielsweise wenn Lagerbewegungen per Transponder überwacht werden. Ein Beispiel ist die automatisierte Überwachung der Lagerbewegungen mit Hilfe von Transpondern. Die IT-Unterstützung ermöglicht außerdem durch Funktionen wie automatisierte Workflows eine reibungslose Zusammenarbeit zwischen den einzelnen Abteilungen, in denen die Informationen anfallen, die dann zentral zusammengetragen werden. So wird verhindert, dass Schritte bei der Datenerfassung vergessen werden.
Wenn beispielsweise für einen neuen Kunden Stammdaten angelegt werden, wird der verantwortliche Sachbearbeiter in der Debitorenbuchhaltung automatisch dazu aufgefordert, die Kreditwürdigkeit des neuen Kunden zu überprüfen. Ist das geschehen, erhält wiederum der zuständige Mitarbeiter, der die Kreditlimits festlegt, automatisch einen entsprechenden Hinweis. Erst nach Abschluss des gesamten Prozesses, ist die Datenaufnahme komplett.
Diese Art von Automatisierung ermöglicht die Realisierung weiterer Vorteile: Prozesse werden beschleunigt und die Mitarbeiter erreichen eine höhere Produktivität, wenn nicht alles immer wieder neu durchdacht werden muss, sondern einmal für alle weiteren Fälle festgelegt wird. Darüber hinaus werden Fehler bei der Datenübertragung minimiert und letztlich durch schneller ablaufende Vorgänge die Kundenzufriedenheit erhöht.
Tipp 9: Gezielte Archivierung reduziert die Datenbestände
 Es ist wichtig, darauf zu achten, dass der Datenbestand, mit dem das Unternehmen im Tagesgeschäft arbeitet, nicht umfangreicher wird als nötig. Mit steigendem Datenvolumen steigt auch der Aufwand, durch Data Cleansing die Qualitätsstandards zu sichern.
Es ist wichtig, darauf zu achten, dass der Datenbestand, mit dem das Unternehmen im Tagesgeschäft arbeitet, nicht umfangreicher wird als nötig. Mit steigendem Datenvolumen steigt auch der Aufwand, durch Data Cleansing die Qualitätsstandards zu sichern.
Außerdem wird es zunehmend schwieriger, die Datensätze zu nutzen. Aus diesem Grund besteht eine wichtige Maßnahme darin, inaktive Artikel zu identifizieren und aus den Datenbeständen zu entfernen. Mit einer automatisierten Stammdatenarchivierung ist es möglich, das Datenvolumen zu begrenzen. Alle Datensätze, die man nicht mehr aktiv benötigt, sollten automatisch archiviert werden. Datenverlust wird somit verhindert und die Datenbank bleibt handhabbar.
Auf die Archivierung kann nicht verzichtet werden, denn auch wenn die Informationen für das aktive Geschäft keine Rolle mehr spielen, müssen sie aufgrund bestehender Nachweispflichten gegenüber den Kunden und Behörden weiterhin gespeichert werden. Ein wesentlicher positiver Nebeneffekt dieser Vorgehensweise besteht darin, dass die Informationsqualität enorm steigt, wenn nur aktive Artikel in Auswertungen einbezogen werden. Des Weiteren wird selbstverständlich die Datenpflege erleichtert und die Integration und Aktualisierung des Systems laufen ebenfalls reibungsloser ab.
Tipp 10: Regelmäßige Mitarbeiterschulungen
 Regelmäßige Schulungen sind wichtig, damit die Mitarbeiter technisch immer auf dem neuesten Stand sind und auch fortwährend für das Thema sensibilisiert werden. Weiterbildungen betonen die Relevanz einer Aufgabe und sorgen dafür, dass dieser Aufgabe die nötige Aufmerksamkeit und Sorgfalt zuteilwird.
Regelmäßige Schulungen sind wichtig, damit die Mitarbeiter technisch immer auf dem neuesten Stand sind und auch fortwährend für das Thema sensibilisiert werden. Weiterbildungen betonen die Relevanz einer Aufgabe und sorgen dafür, dass dieser Aufgabe die nötige Aufmerksamkeit und Sorgfalt zuteilwird.
Besondere Beachtung sollte bei den Schulungen auf alle Tatbestände gelegt werden, die nicht über Automatismen regelbar sind, bei denen die einheitliche Beachtung jedoch ganz entscheidend ist. Das Thema „Schreibweisen“ fällt in diesen Bereich.
Eine einheitliche Schreibweise zu gewährleisten, ist deshalb eine Aufgabe der regelmäßigen Schulungen.
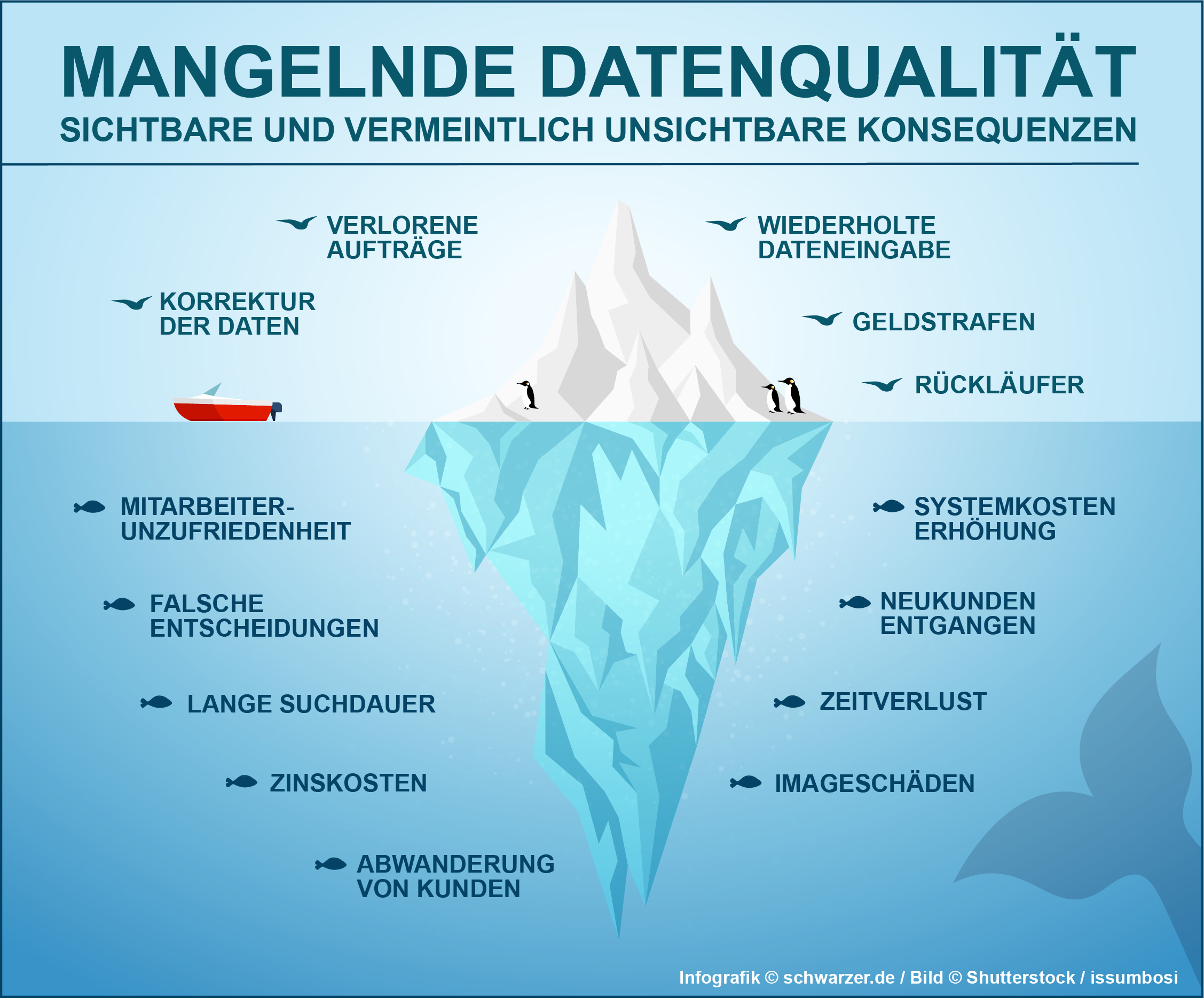
Infografik Mangelnde Datenqualität: Sichtbare und vermeintlich unsichtbare Konsequenzen
Erfolgsfaktor Datenqualität
Aus einer Flut von Unternehmensdaten und externen Quellen mit Hilfe intelligenter Business Intelligence Tools handlungsrelevante Informationen abzuleiten, ist eine strategisch wichtige Aufgabe für das Management. Zu Beginn des Prozesses steht die Datenaufnahme. Wenn schon in dieser Phase aufgrund von mangelnder Verbindlichkeit eine Festlegung von Kriterien und Strukturen fehlt, kann keine hohe Datenqualität gewährleistet werden.
Die Auswirkungen einer unzureichenden Datenqualität sind schwer zu beziffern und aus diesem Grund scheuen viele Firmen die Zeit, Mühe und nicht zuletzt die Kosten, die damit verbunden sind, eine ganzheitliche Strategie zur Erhöhung der Datenqualität durch Datenbereinigung zu implementieren.
Betrachtet man die zukünftigen Entwicklungen mit der weiter steigenden Vernetzung in- und außerhalb von Unternehmen, wird deutlich, dass allseits angestrebte Themen wie Big Data und Business Intelligence nur dann erfolgreich umzusetzen sind, wenn gleichzeitig die Herausforderung angenommen wird, die Datenflut professionell zu managen.
Es ist damit zu rechnen, dass der Einsatz von BI-Tools in den kommenden Jahren noch wesentlich steigen wird und sich deshalb gravierende Wettbewerbsnachteile für die Firmen ergeben, die diesen Trend versäumen. Die Anwendung der BI-Tools kann jedoch nur gelingen, wenn eine saubere Datenbasis zur Verfügung.
Bildnachweise: Nummerierung 1 – 10: shutterstock – TeddyandMia, Titelbild: shutterstock – agsandrew











